
关键词:机内码 动态编码 字库
因为汉字本身的特点,显示汉字始终是计算机在我国应用普及的一个障碍。最初,为了能在PC机上显示、处理汉字,国人发明了一种硬件设备"汉卡",后来各种各样的采用纯软件技术的中文DOS逐渐成熟,其中、西文软件的运行速度和性能还是有明显的差距。最终在软件进入支持UNICODE、真正实现国际化的WIN95以后,硬件跨入"奔腾"时代,才实现了汉字与西文的统一显示,但是这一切是以硬件资源的飞速发展为前提的。以国际GB2312为例,一、二级汉字库共收录了6000多个汉字,每个字按16×16点阵计算,字模需要占用32字节的存储空间,整个字库的规模在200k字节以上,高点阵(24点阵以上)和矢量字库以及Windows用的TrueType字体的字库规模都是几兆字节大小,这在早期的386时代是难以想象的。单片机因为使用灵活、结构简单、体积小、成本低而在工业和生活中得到广泛应用,也正是因此,它的硬件资源很有 限,寻址和计算机能力都远低于PC机,显示汉字更受限制。人们不满足单片机系统采用LED数码管的简单显示,根据单片机的特点,开发出了很多种汉字显示方法。
1 几种常用单片机显示汉字方法
(1)采用标准字[1]
这种方法仿器中文DOS的办法,将一个标准的汉字库装入ROM存储器,再根据汉字的机内码在字库中寻址,找到对应的字模,提取后送到显示器显示。因为采用了和PC机相同的编码(机内码),软件的开发和维护非常简单,基本上与写PC机软件差不多。而对单片机系统自身的要求则相对高多了,16×16点阵的字库需要256K字节,但是一般8位单片机的寻址能力只有64K字节,要进行存储器扩充,除增加很大一部分硬件成本外,还因为要进行存储器分页管理、地址切换,显示速度明显受影响,而且只能显示一种点阵字体。
(2)直接固化显示字模[2]
将要显示的语句中全部汉字的字模数据依次提取出来,顺序存放在存储器中,当显示时,直接取出字模数据送至显示器即可。这种方法占用空间少,程序实现简单,显示速度快;但是字模数据的提取和存储安排是一件委有繁琐的事件,要想大量显示汉字或进行程序修改几乎是不可能的,软件的可维护性很差。
(3)建立带索引的小字库[3]
将全部要显示的汉字统一建成一个小字库,字库分为2部分:索引素和字模表。索引表由若干定长记录组成,记录的内容为:汉字机内码、地址码、识别码。其中地址码是该汉字字模在字模表中的位置,识别码标志该汉字的点阵形式或字体等。字模表中按素引存放汉字字模。显示汉字时先根据待显汉字的机内码在索引表中寻找,找到对应索引记录后,读出地址码和识别码,再根据此从字模表中读出字模,送显即可。这种方法可根据实际使用对字库进行裁剪,硬件开销较小,但是要进行复杂的查询运算,字多了平均寻找时间就会变长,效率降低。
2 汉字动态编码
综上所述,我们发现:在方法1中,程序员工作量最少,但单片要机的软、硬件开销最大;方法2中,单片机的开销较少,但是编写和维护软件极为困难;方法3,介于二者之间。显然,存储空间、显示速度、软件开发维护件间存在着矛盾。受各种PC机模拟软件的启发,我们提出一种基于PC机预处理的汉字显示方法--汉字动态编码,在实际应用中较好地解决了这一问题。其基本原理如下:建立一种新的编码机制,这个汉字编码是动态的;一个编码不与某个汉字具体相联系,而仅代表某个汉字在字库中的位置(这个位置也是动态的);用该码代替程序里字符串(C语言)或数据段(汇编语言)内汉字的机内码,单处机显示程序可根据这个新的编码直接在专门建立的动态小字库中找到字模,不用进行复杂的寻址、查找等运算,如图1所示。
实现汉字动态编码的过程就是先进行汉字识别,然后建立编码字典、提取字模、建立动态字库、改写机内码。首先扫描一遍程序文件,识别其中的汉字,将它们按出现先后顺序或机内码的大小排序,重复出现的剔除,建立了一个编码字典;根据汉字在编码字典的位置(序号),可以对汉字按区码、位码进行编码,也可以采用其它的方法编码,总之序号与它的动态编码存在一一对应关系;根据字典中每个汉字的机内码依次从PC机的汉字点阵字库中提取字模,顺序存储,建立一个小规模的动态字库,这样每个汉字的字模在字库中的位置就与其在编码字典中的序号、动态编码一一对应了。最后,再扫描一遍程序文件,按照编码字典将每个汉字的机内码改写为对应的动态编码。因为程序文件中的汉字随时会增减,编码随之而变,字库的大小也随时在变。所以称之为动态编码和动态字库。
考虑一般应用场合,1000个左右的汉字即可满足要求,按照汉字动态编码方法所需的字库仅为32K字节大小,只需要1片27256即可,几乎不用增加什么硬件。这样,字库的大小可由汉字的多少控制,程序的编写和维护可以沿用中文系统下的习惯,仅需要编写好的单片机程序用PC机进行一次预处理,程序员从繁杂的汉字处理工作中解放出来,有效地降低了软件和硬件开发成本。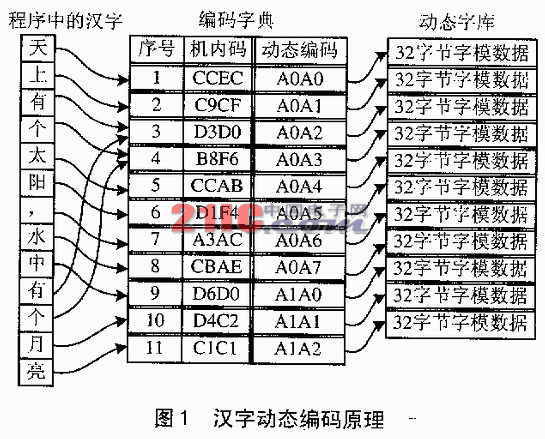
3 汉字动态编码的具体实现
实现汉字动态编码的关键是建立编码字典和改写机内码。下面以是显示1行汉字"天上有个太阳,水中有个月亮"为例,说明动态编码的实现过程。
(1)汉字识别
汉字在PC机内的存储和处理是用机内码来实现的。每个汉字的机内码是唯一的,由2个字节组成,分区码和位码,为了和西文的ASCII码有区别,汉字机内码的区码和位码的取值都大于0A0H。我们要处理的源程序文件都是文本文件,存储的都是西文字符、控制符的ASCII码和中文字符的机内码,当扫描到文件中大于0A0H的字节内容时,即可判断该字节是汉字机内码的1个字节,而且肯定是成对出现,第1个字节是区别,第2个字节是位码,都大于0A0H,否则出错。
在C和汇编程序中表示字符的方式有所不同,但最终字符在文件中的存储格式是一样的。显示上面那行汉字,用C语言可以表示为:
char OneSent[]="天上有个太阳,水中有个月亮";
printfhz(OneSent);/*printfhz()显示函数*/
用十六进制编辑器(我们用的是UEdit32)察看文件中C语言字符串定义语句为:
63 68 61 72 20 20 4F 6E 65 53 65 6E 74 5B 5D 20 3D 20 22 CC EC C9 CF D3 D0 B8 F6 CC AB D1 F4 A3 AC CB AE D6 D0 D3 D0 B8 F6 D4 C2 C1 C1 22 20 3B 0D 0A
用汇编语言可以表示为:
ONESENT:DB ‘天上有个太阳,水中有个月亮‘,00H
MOV DPTR,ONESENT
LCALL DISPLAY;DISPLAY是显示子程序
用十六进制编辑器察看上面用汇编语言定义字符串的那一条语句为:
4F 4E 45 53 45 4E 54 3A 44 42 20 27 CC EC C9 CF D3 D0 B8 F6 CC AB D1 F4 A3 AC CB AE D6 D0 D3 D0 B8 F6 D4 C2 C1 C1 27 2C 30 30 48 0D 0A
由此可以观察到情况确如前所述。
(2)建立编码字典
编码字典是在扫描的同时逐步建立起来的,每扫描到一个汉字(包括全角符号),即与字典中已有的字符进行比较,如没有重复,是新的字符就顺序存入字典,否则继续扫描,直至文件结属。由于每个字符都是从尾部添加的,它们的序号也是依次递增的,根据序号就可以进行动态编码了。由于显示的汉字一般都得在256个以上,即使进行动态编码,也需要用2字节编码来实现。以MCS51系列单片机和16×16点阵汉字做一优化编码示例:8051的地址指针DPTR是16位指针,由高、低2字节指针DPH、DPL组合而成,如果将存储器按0FFH(256)字节分布,修改DPH即可直接寻址到任一页,修改DPL可寻址该页的任一字节。一个16×16点阵汉字的字模是32字节大小,每页存储器正好能容纳8个汉字字模。可以优化设计动态编码的高字节指向字模的页地址(DPH),低字节指向字模在该页的首地址(DPL)。考虑地址空间的有效分配,将字库的地址放在0A000H以后(程序或数据存储器均可),动态编码的高字节要加上地址有效分配,将字库的地址放在0A000H以后(程序或数据存储器均可),动态编码的高字节要加上地址的页偏移量(大于等于0A0H);考虑汉字与西文字符的区别,动态编码的低字节也需要加上一个大于或等于0A0H的偏移量。设某汉字在编码字典中的序号为Num,则该汉字的动态编码为:
动态编码高字节=页偏移量+Num/8
动态编码低字节=偏移量+(Num%8)×32 (1)
偏移量一般可设为0A0H。当单片机显示某个汉字时,只需将其动态编码的高字节送DPH,低字节减0A0H后送DPL,即可得到对应字模的地址指针。
(3)提取字模、建立动态字库
汉字机内码与点阵字库的详细关系可参考有关资料,它们存在如下联系:
字模首地址=((机内码高字节-1)×94+(机内码低字节-1))×N (2)
注:N为一个汉字点阵字模的字节数。
按照编码字典内容,根据字模首地址,依次取出汉字字模,顺序写入一个二进制文件,即建成动态字库(其它方法略),用烧录器写入EPROM,就可以使用了。
(4)编码改写
机内码是PC机识别处理汉字用的,单片机只能处理我们建立起来的动态编码,还得把程序中汉字的仅机码根据编码字典改成对应的动态编码才行。由于在编写源程序的文本编辑器中看到的是经过系统处理过的字节,看不到汉字的机内码,也无法对其进行改写。根据"汉字识别"一节所述,不经过文本编辑器,直接将动态编码(十六进制数)定改磁盘文件对应位置即可,但是处理过后的汉字在文本编辑器里会显示出乱码。
(5)汉字显示
在明白了动态编码与动态字库中字模的关系后,可以完成按照PC机下汉字显示原理进行单片机下的程序设计,编写前面的函数printhz()或子程序的DISPLAY,可参考相关资料[4]。
4 MCS51汉字显示例程
根据上述汉字动态编码方法,我们利用Borland C++编写了PC机预处理程序,将ASM51或C51源程序用PC机预处理后,建立了动态字库和改写了机内码,并且用ASM51写了一个针对MCS51进行优化的子程序DIS_CHAR。它显示一个西文或中文字符,实现过程如图2所示。
西文字符码的显示与流字显示基本相同,将西文字库(仅数字和字符部分)装入程序存储器中,根据ASCII码的值计算出字模首地址,将字符字模依次读出,再送显示即可。
此方案不但可用于单片机系统中,还可应用于任何无中文系统支持的嵌入式系统中。根据这个思路还可设计出不同字体、点阵混合的字库,支持包含2万多个字符的新国标编码,甚至矢量字体在单片机系统中的应用也成为可能。由于技术水平有限,此方案还存在一些不足之处,如改写编码后源程序中汉字显示为乱码,不知道改码处理是否正确,操作比较繁琐。如果能采用插件技术实现此方案,编辑器中能正常显示汉字,而输出已经是改码后的程序文件,则能很好地解决上述不足。在这里,我们抛码引玉,希望有兴趣的朋友一起合作,实现单片机中文显示的广义开发平台。
 返回顶部
返回顶部 刷新页面
刷新页面 下到页底
下到页底